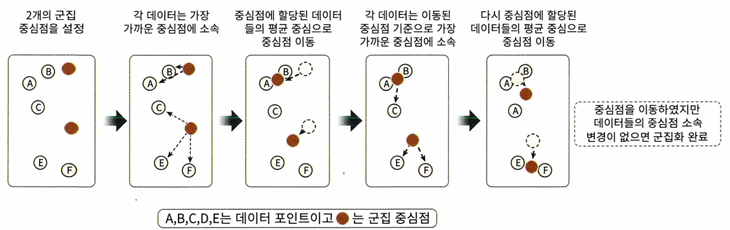
NLP (National Language Processing) : 머신이 인간의 언어를 해석하는 데 더 중점을 두고 기술을 발전하기 위해 통계학과 다양한 딥러닝 기술들을 적용하여 연구하는 분야텍스트 분석자연어처리의 결과물인 언어모델을 활용하여 텍스트 형태로 된 비정형 텍스트에서 고객의 경향성이나 선호도 등 유의미한 정보를 얻어내기 위한 분석 기법텍스트 분류감성 분석텍스트 요약텍스트 군집화01 텍스트 분석 이해머신러닝 알고리즘은 숫자형의 피처 기반 데이터만 입력받을 수 있다. 따라서 비정형 데이터에서 피처 형태로 추출하고 추출된 피처에 숫자값을 부여할 수 있어야 한다.텍스트 사전 준비 작업 (텍스트 전처리) : 클렌징, 대/소문자 변경, 특수문자 삭제, 토큰화, 텍스트 정규화피처 벡터화 / 추출 : 가공..